strand原理分析
在分析strand之前先了解一下背景环境
网络服务编程中对于网络IO的操作有两种线程模型
-
单线程
所有的连接都由一个线程完成,这个线程负责监听、连接、对已连接的socket进行读写,业务逻辑也使用这个线程
-
多线程
对于网络使用多线程通常这样划分,监听使用一个线程,连接使用一个线程,对于已连接的socket进行读写使用多个线程
socket的线程安全性
在分析之前,有必要确定一件事,就是socket的线程安全性,socket本身是线程安全的
以TCP为例,当一个线程A写数据【1,2,3】,线程B再对这个socket写数据会阻塞住,当线程A写完数据后线程B对这个socket写数据【4,5,6】,那么接收端收到的数据就是【1,2,3,4,5,6】, 并不会出现【1,4,2,5,3,6】
但是接收端收到的数据顺序有可能出现【4,5,6】【1,2,3】,如果这样的话就是线程B先写数据【4,5,6】,然后线程A再写数据【1,2,3】
多个线程对一个已连接的socket进行读写操作
这个小结重点分析多个线程对一个已连接的socket进行读写操作的问题,如果单纯的使用一个线程对一个已连接的socket进行读写操作,那么就不会有下面问题
如果多个线程对一个已连接的socket进行读操作,这种方案通常不可取的,对socket本身读写操作是保证原子性,但是试想有两个线程A和B,那么A线程读取了4个字节,B线程读取了1个字节, 当两个线程将这些字节放入buffer池时,怎么确定是4字节在前还是1字节在前呢?在接收数据buffer池中的顺序无法保证,通常使用一个线程对已连接的socket进行读操作
如果多个线程对一个已连接的socket进行写操作,写操作需要数据,数据的产生可能来自于其他线程,也可能来自于处理写操作的线程(处理写操作的线程也是生产数据的线程),这里就引入了多生产者-多消费者概念, 即多个生产线程生产数据(数据归属于一个连接),多个消费线程向socket写数据
例如生产线程A对一个已连接socket生产了24字节的消息,生产线程B对一个已连接socket生产了52字节的消息,多个消费线程向这个socket发送这些消息
在多生产者和多消费者之间存在着一个同步消息队列,同步消息队列有两种方式实现
-
一种是实现一个buffer池
生产线程向buffer池写数据,消费线程从buffer池读数据并通过socket将数据发送出去
-
一种是实现一个类型为函数对象的FIFO队列
生产线程向队列push一个函数对象,函数对象内部对这个socket写数据,消费线程从FIFO队列取出函数对象并且执行这个函数对象,也就是说对这个socket写数据的操作是在消费线程完成的
不管上面哪一种同步消息队列都需要互斥锁,下面对多生产者-多消费者使用每一种同步消息队列进行分析
-
多生产者-多消费者使用buffer池
多生产者-多消费者使用两个条件变量,一个是消费者条件变量,一个是生产者条件变量,关于条件变量可以参考这篇文章,顺序如下:
-
当生产线程P1产生数据,抢互斥锁,向buffer池写完数据,通知消费线程
-
消费线程C3抢到了互斥锁,从buffer读数据,通过socket发送一部分数据,发送数据大小取决于send接口返回,此时通知生产线程
数据按照向buffer池写入顺序通过socket发送出去了,但是消费者线程有必要是多线程吗?,当生产线程通知消费线程,必然导致多个消费线程同时争抢互斥锁,只有一个会抢到,而通过socket发送数据时 也只能一个线程先写,所以多个消费者线程争抢倒不如就一个消费线程负责发送数据,那么模型也就变成了【多生产者-单消费者】
这里有个问题是:当消费线程通过socket发送数据时,也就意味着buffer池被消费线程锁定了,进一步证明所有的生产线程此时在阻塞状态,不论是【多生产者-多消费者】还是 【多生产者-单消费者】,这种模式无异于同步IO操作,即一个线程既扮演着生产者的角色又扮演着消费者的角色
尝试解决上面提到问题,假设先通知生产线程,再通过socket发送一部分数据,上面的步骤就变成如下:
-
当生产线程P1产生数据,抢互斥锁,向buffer池写完数据,通知消费线程
-
消费线程C3抢到互斥锁,从buffer读数据,释放锁,此时通知生产线程
-
消费线程C3通过socket发送一部分数据,发送数据大小取决于send接口返回
这里又产生了两个问题: 消费线程C3从buffer读数据,读多少数据呢?如果读了64字节数据,而实际通过socket发送了32字节,剩下的32字节数据怎么处理?第二个问题下面小结会提到
-
-
多生产者-多消费者使用类型为函数对象的FIFO队列
多生产者-多消费者使用两个条件变量,一个是消费者条件变量,一个是生产者条件变量,当生产线程产生数据,抢互斥锁,向FIFO队列插入函数对象,函数对象内部使用socket发送数据, 通知消费线程,消费线程抢互斥锁,从FIFO队列提取一个函数对象,注意提取完一个函数对象就释放互斥锁,通知生产线程,执行函数对象,函数对象内部使用socket发送数据,伪代码如下:
// 生产者线程 void SendMessage(std::unique_ptr<message_base> message) { { std::lock_guard<std::mutex> lock(mutex_); fifo_.push_back([message = std::move(message)] { ... // IO操作 socket.send(message) }); } consumer_condition_variable.notify_all(); } // 消费者线程 bool Run() { while(true) { std::function<void()> func_object; { std::unique_lock<std::mutex> lock(mutex_); if (!consumer_condition_variable.wait_for(lock, wait_duration, [this] { return !this->fifo_.empty(); })) { return false; } func_object = std::move(fifo_.front()); fifo_.pop_front(); } pop_cv_.notify_one(); // 执行函数对象 func_object(); } }这种模型似乎解决了同步IO操作的问题,执行socket发送时并没有阻塞生产线程,但是这里也有个问题,例如:
-
生产线程P1产生数据,抢到锁,向队列插入一个函数对象F1,通知消费线程
-
消费线程C1抢到锁,消费线程C1提取完一个函数对象F1,释放锁后,通知生产线程,正在执行函数对象F1
-
生产线程P1又抢到锁,向队列插入一个函数对象F2,通知消费线程
-
消费线程C2抢到锁,消费线程C2提取完一个函数对象F2,释放锁后,通知生产线程,正在执行函数对象F2
如果第2步的消费线程C1,正在执行函数对象F1时,消费线程C2也正在执行函数对象F2,如果这个两个函数对象对同一个socket执行数据发送,那么是F2的数据先被发送还是F1的数据先被发送?如果同一个socket的数据发送没有 顺序依赖当然没问题,如果对同一个socket数据发送有顺序依赖,则肯定有问题,按照刚才的分析,有可能业务层【后生产的数据】比【先生产的数据】先到
如果先执行函数对象,再通知生产线程,不可以吗?这不就又回到【多生产者-多消费者使用buffer池】小结里提到的问题了吗?先通知再执行函数对象就是要实现异步IO操作
-
解决上面两个方案提到的问题,可以使用【多生产者-单消费者】+【消费者先通知生产者,再socket发送】达到了异步IO操作,这里的单消费者就是一个线程,也就是说一个连接就是一个线程,那么一个服务有成千上万的连接,不可能 为每个连接分配一个线程,所以希望:
-
有固定数量的线程来处理所有的连接的数据发送,即:有多个消费者线程
-
这些固定数量的消费者线程等待同一个条件变量的通知
-
每个连接有有一个数据队列(其实是两个数据队列,发送数据队列和接收数据队列)
-
每个消费者线程共用同一个队列,队列里的元素就是【每个连接的数据队列】
-
对于每个连接的数据发送要异步的、顺序的,即:数据的发送真正的由消费线程来发送,并且保证顺序
-
尽量减少对生产线程的阻塞,所以当消费线程从一个连接的数据队列提取数据后,立即通知生产线程,然后再进行数据发送
-
为了保证一个连接数据发送的顺序,例如:当一个连接的发送数据队列有64条数据需要发送,那么这些数据必须保证在同一个消费线程完成,在发送完这些数据之前,如果有生产线程对这个连接产生数据那么也依然是这个消费线程来发送
所以当一个消费线程锁定了一个连接的发送数据队列,那么必须全部清空队列后才彻底释放对这个队列的锁,也就意味着当清空这个连接的数据队列后, 如果这个连接的数据队列又有数据后,有可能是另外一个消费线程负责清空这个连接的数据队列了,和上一次清空【这个连接的数据队列】的消费线程不是同一个了
那么这也就是strand所做的工作
strand
参照上面提到的要求,可以参照下图来更好的理解strand原理:
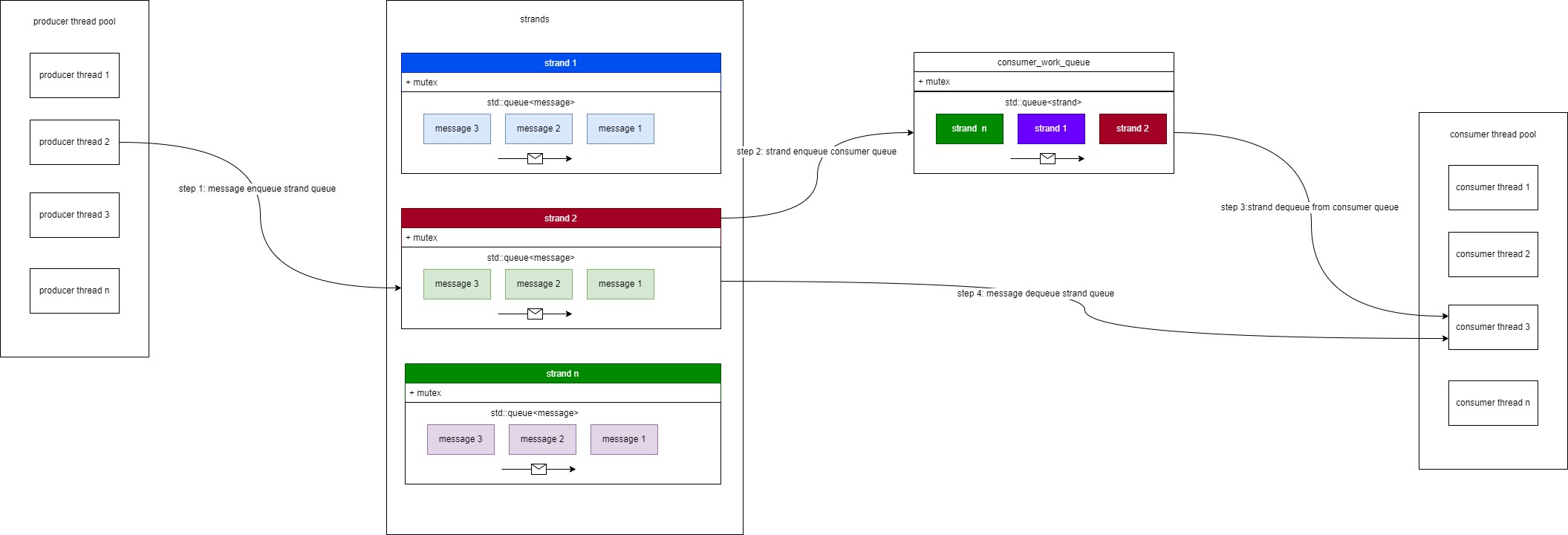
这里的strand可以理解为一个socket连接,结合图列出下面strand工作大概流程:
- 任何生产线程可以向一个strand内的消息队列插入数据
- 当插入数据时将这个strand插入消费者线程strand队列,图中的cosumer_work_queue,并且通知消费者线程
- 消费者线程从strand队列提取一个strand,从这个strand内的消息队列提取数据,并处理,直到这个strand内的消息队列没有数据
大概的流程就是这样,这里有很多细节需要分析
-
strand内互斥锁
从图中看到,每个strand内都有一个互斥锁,有可能多个生产者线程同时向这个strand(socket连接)插入消息,也有可能消费者线程和生产者线程争抢这个消息队列, 消费线程提取,而生产线程插入
-
cosumer_work_queue内的互斥锁
有可能多个strand同时向cosumer_work_queue内strand队列插入,所以这个也需要加锁
-
从上面小结得知为了减少对生产线程的阻塞,那么当消费线程从strand内的消息队列提取一个数据后,应该立即释放strand内锁
-
当消费线程从cosumer_work_queue内strand队列提取完一个strand后,也应该立即释放cosumer_work_queue内的互斥锁,不会阻塞其他消费线程继续提取, 或者不会阻塞其他生产线程继续向cosumer_work_queue内strand队列插入
没有代码实现的原理,就像大树没有根基,还有很多细节需要代码配合进行分析,这里是strand代码实现,以及作者对strand的分析
strand源码分析
源码中涉及到的条件变量、多生产者-多消费者模式可以参照这篇文章
strand是个模板类,而模板类型就是类WorkQueue,每个strand都会持有同一个类WorkQueue对象的引用,所有消费线程调用这个类WorkQueue对象的Run函数, 类WorkQueue Run函数内会从消费者队列(cosumer_work_queue)提取一个strand,进而达到多消费者的目的
从生产者的角度出发,当有数据向strand内消息队列插入时,strand则将自己插入WorkQueue内strand队列,
注意strand内的消息队列是Monitor<Data>,Monitor其实是对Data的一层有锁的包装,Data内包含了标准库的std::queue,
同时Data包含了bool型的变量running_,稍后会分析这个bool型变量,为了方便分析,下面代码已经将
模板替换为实际类型了
class Strand
{
...
struct Data
{
bool running_ = false;
std::queue<std::function<void()>> queue_;
};
Monitor<Data> monitor_;
WorkQueue& processor_;
}
class Monitor
{
private:
mutable Data t_;
mutable std::mutex mutex_;
public:
using Type = Data;
Monitor()
{
}
Monitor(Data t) : t_(std::move(t))
{
}
template <typename F>
auto operator()(F f) const
{
std::lock_guard<std::mutex> hold{ mutex_ };
return f(t_);
}
};
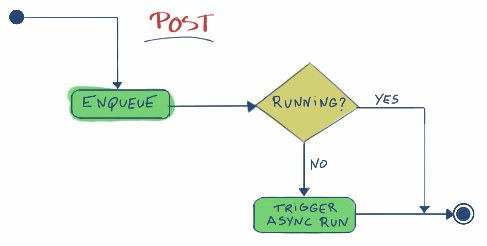
Monitor内的函数auto operator()(F f) const使Monitor变成callable,就是说strand内的Monitor变量monitor_可以这样被使用monitor_(…),根据函数operator()内部实现得知, 当外部调用函数operator()时,先对消息队列加锁,抢到锁,则调用外部传递的函数对象,函数的参数是Data&,外部进而可以向Data内的std::queue插入数据了,这一步用到的锁就是图中 的strand内的锁mutex,下面是类strand内的Post函数对monitor_的使用:
template <typename F>
void Post(F handler)
{
// We atomically enqueue the handler AND check if we need to start the
// running process.
bool trigger = monitor_([&](Data& data) {
data.queue_.push(std::move(handler));
if (data.running_)
{
return false;
}
else
{
data.running_ = true;
return true;
}
});
// The strand was not running, so trigger a run
if (trigger)
{
processor_.Push([this] { Run(); });
}
}
类Monitor的函数auto operator()(F f) const参数f其实就是[&](Data& data) {...},函数f的返回值为bool,当函数f被调用也就意味着Data内的消息队列被当前线程锁定了,
所以函数f内可以向Data内的消息队列插入数据了data.queue_.push(std::move(handler));,从插入函数下面代码得知函数f的返回值由变量running决定,如果running是false则返回true
,如果running已经是true,则返回false,Post函数会根据这个返回值来决定是否向类WorkQueue内strand队列插入,processor_.Push([this] { Run(); });就是将strand插入
类WorkQueue内strand队列,进而得知strand内的Run函数是由消费线程调用的
所以类Data内的bool变量running标识了是否已经将strand插入类WorkQueue内strand队列,这样做是防止一个strand被多次插入到类WorkQueue内strand队列, 那么类Data内的bool变量running什么时候被设置为false呢?从上面的分析和代码实现得知,当strand内消息队列全部被清空才将Data内的bool变量running标识为false,也就是类strand 内的Run函数内
void Run()
{
typename Callstack<Strand>::Context ctx(this);
while (true)
{
std::function<void()> handler;
monitor_([&](Data& data) {
assert(data.running_);
if (data.queue_.size())
{
handler = std::move(data.queue_.front());
data.queue_.pop();
}
else
{
data.running_ = false;
}
});
if (nullptr == handler)
{
return;
}
handler();
}
}
这段代码data.running_ = false;,到这里我们应该知道消费线程才会调用类strand内的Run函数,所以类strand Run函数内再次调用monitor_(…),
进而消费线程也参与与生产线程争抢strand内的消息队列锁,这就是上面提到的生产线程与生产线程会争抢strand内的消息队列锁,消费线程与生产线程争抢strand内的消息队列锁
上面其实也是对strand内的Post函数和Run函数的工作流程分析,下面是Post函数的流程图:
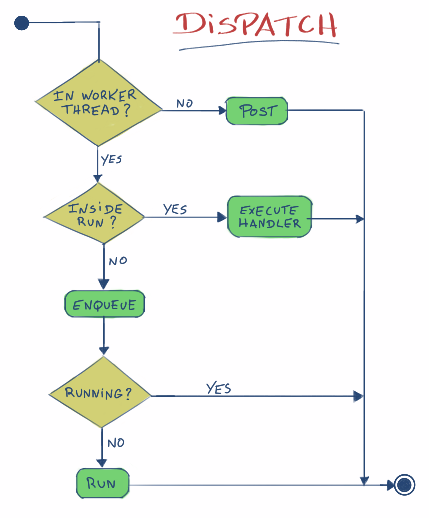
strand内的Dispatch是最精彩的函数,在分析Dispatch函数之前先了解一个现实问题,以网络服务为例, 通常使用一个固定的线程池来供网络服务使用,也就是说处理已连接的socket的线程从这个线程池里分配,负责数据发送的消费线程也从这个线程池里分配, 那么也就是说一个线程有可能是生产线程也有可能是消费线程,这里有些细节需要分析:
- 如果生产线程也产生数据向生产线程插入数据时,发现生产线程是消费线程会怎么处理,发现生产线程不是消费线程又怎么处理
- 如果发现生产线程是消费线程,那么这个线程正在处理strand内数据又怎么处理
这些问题可以从dispatch函数中找到答案,代码如下:
template <typename F>
void Dispatch(F handler)
{
// If we are not currently in the processor dispatching function (in
// this thread), then we cannot possibly execute the handler here, so
// enqueue it and bail out
if (!processor_.CanDispatch())
{
Post(std::move(handler));
return;
}
// NOTE: At this point we know we are in a worker thread (because of the
// check above)
// If we are running the strand in this thread, then we can execute the
// handler immediately without any other checks, since by design no
// other threads can be running the strand
if (RunningInThisThread())
{
handler();
return;
}
// At this point we know we are in a worker thread, but not running the
// strand in this thread.
// The strand can still be running in another worker thread, so we need
// to atomically enqueue the handler for the other thread to execute OR
// mark the strand as running in this thread
auto trigger = monitor_([&](Data& data)
{
if (data.running_)
{
data.queue_.push(std::move(handler));
return false;
}
else
{
data.running_ = true;
return true;
}
});
if (trigger)
{
// Add a marker to the callstack, so the handler knows the strand is
// running in the current thread
typename Callstack<Strand>::Context ctx(this);
handler();
// Run any remaining handlers.
// At this point we own the strand (It's marked as running in
// this thread), and we don't release it until the queue is empty.
// This means any other threads adding handlers to the strand will
// enqueue them, and they will be executed here.
Run();
}
}
函数内这段代码就是判断调用dispatch函数的线程是否为消费者线程,如果不是消费者线程则调用post函数
if (!processor_.CanDispatch())
{
Post(std::move(handler));
return;
}
源码的WorkQueue类成员函数Run是消费者线程的入口函数,函数内的第一行代码Callstack<WorkQueue>::Context ctx(this);就是
消费者线程标识,dispatch内判断当前线程是否为消费者线程代码!processor_.CanDispatch(),就是调用WorkQueue内的成员函数
bool CanDispatch()
{
return Callstack<WorkQueue>::Contains(this) != nullptr;
}
一个生产者线程自然不会让WorkQueue的Run作为入口函数,如果生产线程调用dispatch函数时,函数CanDispatch()肯定会返回false
如果一个消费者线程调用dispatch函数时,函数CanDispatch()肯定会返回true,逻辑会继续向下运行,会遇见下面这段代码
// If we are running the strand in this thread, then we can execute the
// handler immediately without any other checks, since by design no
// other threads can be running the strand
if (RunningInThisThread())
{
handler();
return;
}
这段代码的逻辑是:当消费者线程产生数据,调用dispatch函数,并且这个消费者线程正在处理这个strand队列,满足这些条件才会进入判断体内, 并且立刻会执行传入的函数对象,这里有两个问题:
-
什么业务场景下会触发这段逻辑
考虑如下场景:消费线程处理strand队列的函数对象时,其中一个函数对象又生产了数据并且调用dispatch函数,伪代码如下:
[code = code]() { if(code == 1) { dispatch([]{...}); } }代码
dispatch([]{...});对dispatch的调用就会进入上面的判断体内 -
进入这段逻辑会出现插队现象
当进入上面的判断体内也就意味着出现插队现象,例如strand队列为[1,2,3,4],当执行到2时,出现了再次dispatch的情况,最后strand队列函数对象的执行顺序为: 1、2-dispatch、2、3、4
这种逻辑是需要做到心中有数的
如果不进入if (RunningInThisThread())判断体内,继续运行下面的逻辑,dispatch函数内这段代码很好理解:
auto trigger = monitor_([&](Data& data)
{
if (data.running_)
{
data.queue_.push(std::move(handler));
return false;
}
else
{
data.running_ = true;
return true;
}
});
消费者线程产生数据调用dispatch函数,第一个抢到锁的消费者线程将running_设置为true,其他消费者线程产生数据调用dispatch函数时则插入队列,第一个抢到锁的消费者线程 传入的函数对象在下面代码执行
if (trigger)
{
// Add a marker to the callstack, so the handler knows the strand is
// running in the current thread
typename Callstack<Strand>::Context ctx(this);
handler();
// Run any remaining handlers.
// At this point we own the strand (It's marked as running in
// this thread), and we don't release it until the queue is empty.
// This means any other threads adding handlers to the strand will
// enqueue them, and they will be executed here.
Run();
}
第一个抢到锁的消费者线程进入if (trigger)判断体内,为什么判断体内会又一次标识这个strand正在运行typename Callstack<Strand>::Context ctx(this);?
在strand的成员函数Run内不是已经标识了吗typename Callstack<Strand>::Context ctx(this);?正如作者的注释,
为了在执行handler()时而做的标识,因为handler内有可能再次调用dispatch函数,和上面的代码if (RunningInThisThread())相呼应
为什么第一个抢到锁的消费者线程不将函数对象也入队呢?这样不就省去了这段代码typename Callstack<Strand>::Context ctx(this); handler();吗?修改后代码如下:
auto trigger = monitor_([&](Data& data)
{
data.queue_.push(std::move(handler));
if (data.running_)
{
return false;
}
else
{
data.running_ = true;
return true;
}
});
if (trigger)
{
// Run any remaining handlers.
// At this point we own the strand (It's marked as running in
// this thread), and we don't release it until the queue is empty.
// This means any other threads adding handlers to the strand will
// enqueue them, and they will be executed here.
Run();
}
这样不就做到了通用处理了吗?我猜测作者是要省去入队出队的操作,而是直接执行,毕竟入队出队也有开销,这种开销在数据量小的时候并不明显,在数据量大时开销非常明显
判断体内if (trigger)对于函数Run()的调用也就意味着第一个调用dispatch函数的消费者线程直接运行这个strand队列,在运行这个strand队列过程中如果有其他
消费者线程产生数据插入这个strand队列,那么也由第一个调用dispatch函数的消费者线程处理
下图是dispatch函数流程
strand总结
-
以已连接socket为例(一个已连接为一个strand),strand保证了对一个已连接的顺序执行,注意上面提到的插队现象,业务逻辑层向strand的插入顺序strand本身保证不了, 这是由业务逻辑层保证的
-
每次执行strand队列元素的消费者线程不一定保证和上一次执行的消费者线程是同一个线程,但是单次执行strand队列时,队列内的所有元素保证是在同一个消费线程执行的
-
当需要多生产者-多消费者线程模型处理多个对象,同时对于同一对象的执行又要求顺序性,则可以选择strand