log系统
职业生涯中涉及的服务端业务场景都需要log系统,Go服务、C++游戏服务器都需要一个完备的log系统,目前接触最多的就是用这两种语言写的服务,所以以这两种语言分别实现了log系统。
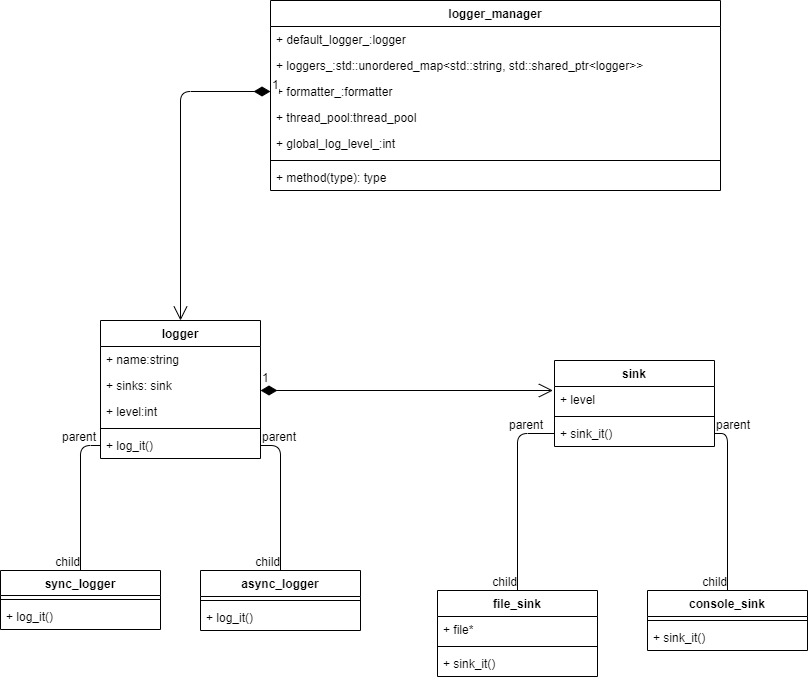
实现log系统之前肯定需要列出log系统模型
log系统模型
这篇文章简单提到了log系统的设计思想,下面列出详细:
-
业务线程(生产者)产生log数据
假设此线程为1#线程
-
log系统处理log数据(消费者)
写log消息的线程为2#线程
log系统实现真正的异步写log,注意:写log消息的2#线程和1#线程是两个不同的线程
既然是两个不同的线程就涉及到消息队列,传统做法通过加锁实现,这样势必可能造成业务线程阻塞,还有一种做法是使用无锁队列, 下面会以这两种方法做测试
-
需要支持按天、按大小生成log文件
通常需要每天产生一个log文件,即当日00:00:00需要创建log文件
有时需要按照大小重新生成log文件,例如超过10M即重新创建
-
需要支持不同的logger
通常有个主logger,而实际生产中有需求需要与主logger的日志分开,例如游戏服务器中的AI模块产生的log消息需要单独记录,便于分析问题
不同logger需要产生不同的log文件
不同logger可以自定义输出方式,例如一个logger可以只控制台输出,也可以只文件输出,也可以是既控制台输出也文件输出
-
log消息的内容
log消息的内容需要包含以下:
-
产生log消息的时间
-
产生log消息的业务线程ID
-
log级别
-
产生log消息的文件、函数、行数
-
用户层的消息内容
-
-
log消息需要支持流式写入
这个是可选项,流式写入就像下面这种形式:
LOGERR()<<"log msg,id:%d,name:%s"<<id<<name;非流式写入就像下面这种形式:
LOGERR("log msg,id:%d,name:%s",id,name); -
log系统支持同步写log数据
可以同步写log数据,意味着业务线程(生产者)直接将log数据按照给定的输出方式(控制台、写log文件)进行输出
直观表现
结合上面的模型可以log系统产生的log数据直观表现:
-
log文件名
LoggerName-2021-04-20-00-00-00.log
-
log内容
2021-04-20-00-00-00 thread_id log_level file_name funtion_name line_number log_msg
开源log比较
使用c++语言开发的log系统有glog、log4cxx、spdlog、g3log,使用Go语言开发的log系统,目前最流行、也是最快的是zerolog
先分析使用C++语言开发的log系统
-
log4cxx
log4cxx支持最丰富,提供了log属性配置,可以配置具体logger,logger输出方式,输出方式log级别,输出格式,输出目录,log文件大小 具体可以看下面的配置:
// 主logger log4j.rootLogger=debug,stdout // test logger log4j.logger.test=debug // testex logger log4j.logger.testex=debug,R log4j.additivity.testex=false // stdout输出方式 log4j.appender.stdout=org.apache.log4j.ConsoleAppender log4j.appender.stdout.layout=org.apache.log4j.PatternLayout log4j.appender.stdout.Threshold=info # Pattern to output the caller's file name and line number. log4j.appender.stdout.layout.ConversionPattern=%5p [%d] - %t %m %n // 文件滚动式输出方式 log4j.appender.R=org.apache.log4j.DailyRollingFileAppender log4j.appender.R.DatePattern='.'yyyy-MM-DD log4j.appender.R.File=../log/log.log log4j.appender.R.Threshold=info log4j.appender.R.MaxFileSize=1GB # Keep one backup file log4j.appender.R.MaxBackupIndex=10 log4j.appender.R.layout=org.apache.log4j.PatternLayout log4j.appender.R.layout.ConversionPattern=%5p %c [%d] - %t %m %nlog4cxx对apr库和apr-util有依赖
-
spdlog
spdlog 和log4cxx相比只是缺少了对log属性配置的支持,spdlog使用了更现代化C++,使用了C++11、C++14、C++17的特性,结构非常清晰,可以支持同步log、异步log ,最主要的是集成了一个著名的字符串格式化开源库fmt,对于对字符串的格式一般会有很大的性能损耗,fmt更快、功能更丰富。具体可以查看 fmt的主页,关于spdlog可以参考GitHub主页,spdlog系统的代码结构图大致可以参考如下:
-
g3log
g3log和spdlog、log4cxx相比较而言功能缺失了很多,没有丰富的输出方式,没有logger的管理,不支持同步log,代码结构不清晰, 消息内容的格式化使用标准库的string,其效率与开源库fmt相比非常慢,如果想要达到上面的要求需要自己修改源码并且做外层封装, 源码本身和工业产品差距很大
g3log的性能测试显示比spdlog的性能更稳定,最大延迟几乎和平均值相同,这是g3log作者给出的测试结果,这项测试报告是作者在2015年6月30日给出 的,而写此文章是2021年9月8日,这已经过去了6年之久,spdlog更新了很多版本,6年前的测试结果不能作为参考依据,所以下面一节会专门针对 g3log和spdlog做出测试,这里是g3log作者给出测试报告,这里是g3log的github仓库地址
g3log和spdlog性能对比
记录每个线程每条log写入log消息队列的时间
选择出写入一条log消息到消息队列的最长时间
记录全部写入消息队列的总时间
注意这里并没有统计实际全部写完到log文件的时间,也就是说生产线程产生的log消息全部写入消息队列后,消费线程并没有结束,还有log消息未被写入log文件
-
win 10系统,Intel Core i7-8700,3.2GHZ,16G内存
生产线程10个
生产线程总共产生50W条日志
消费线程(向log文件写日志的线程)1个
向消息队列写入平均时间 向消息队列写入总时间 向消息队列写入一条log最长时间 spdlog 10.8684 us 5434 ms 4 ms g3log 18.5792 us 9289 ms 17 ms -
win 10系统,AMD Ryzen 5 4500U,2.38GHZ,16G内存
生产线程10个
生产线程总共产生50W条日志
消费线程(向log文件写日志的线程)1个
向消息队列写入平均时间 向消息队列写入总时间 向消息队列写入一条log最长时间 spdlog 22.7601 us 11380 ms 15 ms g3log 32.9294 us 16464 ms 30 ms -
win 10系统,Intel Core i7-8700,3.2GHZ,16G内存
生产线程10个
生产线程总共产生100W条日志
消费线程(向log文件写日志的线程)1个
向消息队列写入平均时间 向消息队列写入总时间 向消息队列写入一条log最长时间 spdlog 11.4556 us 11455 ms 4 ms g3log 19.4188 us 19418 ms 24 ms -
win 10系统,AMD Ryzen 5 4500U,2.38GHZ,16G内存
生产线程10个
生产线程总共产生100W条日志
消费线程(向log文件写日志的线程)1个
向消息队列写入平均时间 向消息队列写入总时间 向消息队列写入一条log最长时间 spdlog 19.0307 us 19030 ms 36 ms g3log 29.3885 us 29388 ms 25 ms
在windows系统上按照这种方式测试spdlog比g3log快很多,spdlog不论【总时间】还是【一条log的最长时间】都比g3log快很多;唯有在win10系统AMD上在【一条log的最长时间】这一选项上spdlog略有逊色
在测试过程中还发现g3log全部写完log消息到log文件很慢,消费线程很慢,生产线程生产完所有log消息需要等待很长时间消费线程才写完,而spdlog则不会,生产线程、消费线程几乎同时结束
上面的测试是按照【所有线程产生固定数量的日志】,比较下来spdlog性能很高,下面是【每个线程产生固定数量日志】的测试
-
win 10系统,Intel Core i7-8700,3.2GHZ,16G内存
生产线程10个
每个线程产生10W条日志
生产线程总共产生100W条日志
消费线程(向log文件写日志的线程)1个
向消息队列写入平均时间 向消息队列写入总时间 向消息队列写入一条log最长时间 spdlog 11.11 us 11110 ms 4 ms g3log 19.4077 us 19407 ms 21 ms -
win 10系统,AMD Ryzen 5 4500U,2.38GHZ,16G内存
生产线程10个
每个线程产生10W条日志
生产线程总共产生100W条日志
消费线程(向log文件写日志的线程)1个
向消息队列写入平均时间 向消息队列写入总时间 向消息队列写入一条log最长时间 spdlog 18.8616 us 18861 ms 45 ms g3log 30.6464 us 30646 ms 20 ms
关于这项测试还是上面的结论:在win10系统AMD上在【一条log的最长时间】这一选项上spdlog略有逊色,而【总时间】这一项spdlog总是最快, g3log全部写完log消息到log文件很慢,spdlog则不会
spdlog的同步写和异步的测试
从上面的结构看出spdlog的性能要比g3log强很多,无论从总时间还是最坏时间(向消息队列写入一条log最长时间)的比较都表现的很强,下面使用spdlog的同步模式和异步模式进行比较
-
win 10系统,Intel Core i7-8700,3.2GHZ,16G内存
生产线程10个
生产线程总共产生100W条日志
消费线程(向log文件写日志的线程)1个
向消息队列写入平均时间 向消息队列写入总时间 向消息队列写入一条log最长时间 同步 11.0761 us 11076 ms 13 ms 异步 10.9346 us 10934 ms 7 ms -
win 10系统,AMD Ryzen 5 4500U,2.38GHZ,16G内存
生产线程10个
生产线程总共产生100W条日志
消费线程(向log文件写日志的线程)1个
向消息队列写入平均时间 向消息队列写入总时间 向消息队列写入一条log最长时间 同步 30.3326 us 30332 ms 12 ms 异步 18.9964 us 18996 ms 26 ms
目前从window10系统不同的CPU上测试的结果显示,【总时间】这个测试项还是异步最快,在Intel上最坏时间(向消息队列写入一条log最长时间)这个测试项异步的方式最好, 但是在AMD上同步方式更好
spdlog使用无锁队列的测试
这篇文章提到了Cameron的无锁队列,spdlog使用的是有锁、多生产者多消费者队列,使用无锁队列会不会提升性能
-
win 10系统,Intel Core i7-8700,3.2GHZ,16G内存
生产线程10个
生产线程总共产生50W条日志
消费线程(向log文件写日志的线程)1个
队列大小8192
向消息队列写入平均时间 向消息队列写入总时间 向消息队列写入一条log最长时间 有锁队列 10.8684 us 5434 ms 4 ms 无锁队列 10.9523 us 5476 ms 13 ms -
win 10系统,Intel Core i7-8700,3.2GHZ,16G内存
生产线程10个
生产线程总共产生100W条日志
消费线程(向log文件写日志的线程)1个
队列大小8192
向消息队列写入平均时间 向消息队列写入总时间 向消息队列写入一条log最长时间 有锁队列 11.4556 us 11455 ms 4 ms 无锁队列 11.006 us 11006 ms 12 ms
多次测试结果显示总时间差不多,但是【一条log的最长时间】在这一项上使用有锁队列比无锁队列时间要短很多,而且在这一项上无锁队列也不够稳定,最长时间超过了17ms
使用spdlog
-
spdlog与g3log的比较
spdlog提供的功能丰富,代码结构简单易懂,最坏时间、总时间、log消息真正写入log文件时间都比g3log用时要少很多,在Windows AMD平台上最坏时间略高于g3log
在多生产者多消费者的队列设计上,spdlog也优于g3log
spdlog采用两个条件变量——一个生产条件变量,一个消费条件变量。步骤如下:
-
当生产一条log数据时,如果队列满了则通知消费条件变量,如果队列没有满则继续插入
-
当接收到消费条件变量通知,消费一条log数据,然后通知生产条件变量(这样设计我猜测是为了避免长时间阻塞生产线程), 然后继续第1步
而g3log使用单个条件变量,整个过程无规律,当生产一条log数据时,通知这个变量,但是不一定消费者抢到,也可能是生产者抢到,这也可能是g3log将log数据写入log文件慢的原因,
当g3log使用与spdlog同样的多生产者多消费者队列模型时,g3log的写入文件时间和spdlog一样快
spdlog的消息队列采用的是环形队列,内部采用vector,g3log的消息队列采用的是std::queue,vector的元素在栈区分配;而queue的元素在堆区分配,对于queue队列而言 也就意味着每个log消息都要触发new、delete操作,从性能分析报告看出new、delete操作的耗时占很大比重
上面也提到spdlog采用开源库fmt进行log消息的格式化,这也使得spdlog很快的一大原因,而g3log采用标准库的string,从g3log的性能分析报告看出格式化的耗时也占很大比重
当g3log使用与spdlog同样的多生产者多消费者队列,g3log将log数据写入log文件变快了,单条log数据写入队列变快了,大概每条log写入队列最坏的时间是2——3ms, 但是生产线程总体写入时间变慢了,
综上,请使用spdlog
-
-
spdlog同步与异步模式比较
在Windows AMD平台上【异步模式的最坏时间】略高于【同步模式的最坏时间】,【总时间】不论在哪个平台上异步模式用时最少
-
spdlog有锁队列与无锁队列比较
在Windows平台上总时间基本相同,而最坏时间(一条log的最长时间)在这一项上使用有锁队列比无锁队列时间要少很多