处理TCP数据流
这篇文章讲述如何安全的高效的处理TCP数据流,其中包括一些优化方向
检测连接有效性
在编写TCP连接程序时,检测连接有效性是必不可少的环节,防止某一端维护着没有数据读写的“静默”的连接,例如客户端突然崩溃,服务器端可能在几天内都维护着一个无用的 TCP 连接
检测连接有效性有两种方法:
-
打开TCP Keep-Alive 选项
使用系统提供的保持活跃机制Keep-Alive,这个机制描述如下:
定义一个时间段,在这个时间段内,如果没有任何连接相关的活动,TCP 保活机制会开始作用,每隔一个时间间隔,发送一个探测报文,该探测报文包含的数据非常少, 达到系统设置的探测次数时,则认为当前的 TCP 连接已经死亡,系统内核将错误信息通知给上层应用程序,探测过程中如果对端会正常响应,这样 TCP 保活时间会被重置,等待下一个 TCP 保活时间的到来
探测后通常会产生3种结果:
-
对方接收一切正常:以期望的ACK响应。2小时后,TCP将发出另一个探测分节
-
对端程序崩溃并重启。当 TCP 保活的探测报文发送给对端后,对端是可以响应的,但由于没有该连接的有效信息,会产生一个 RST 报文,这样很快就会发现 TCP 连接已经被重置, 服务端程序对RST报文的处理通常选择回收连接
-
尝试9次后对端仍然没有响应,应用程序会收到EHOSTUNREACH——host unreachable这样错误
上面的描述需提供3个变量——保活时间、探测时间间隔、探测次数,这3个变量可以通过下面命令查看:
// 探测时间间隔(默认75s) cat /proc/sys/net/ipv4/tcp_keepalive_intvl // 探测次数(默认9次) cat /proc/sys/net/ipv4/tcp_keepalive_probes // 保活时间(默认7200s) cat /proc/sys/net/ipv4/tcp_keepalive_time或者:
sysctl -a | grep keepalive这个机制默认是关闭的,可以通过如下方式开启:
int keepAlive = 1; setsockopt(listenfd, SOL_SOCKET, SO_KEEPALIVE, (char*)&keepAlive, sizeof(keepAlive));也可以全局修改这3个变量的值:
vi /etc/sysctl.conf net.ipv4.tcp_keepalive_time=7200 net.ipv4.tcp_keepalive_intvl=75 net.ipv4.tcp_keepalive_probes=9保存后,
sysctl -p使其生效,也可以针对单个连接修改:int keepAlive = 1; int keepIdle = 60; int keepInterval = 5; int keepCount = 3; // 开启探活 setsockopt(sockfd, SOL_SOCKET, SO_KEEPALIVE, (char *)&keepAlive, sizeof(keepAlive)); // 保活时间 setsockopt(sockfd, SOL_TCP, TCP_KEEPIDLE, (char*)&keepIdle, sizeof(keepIdle)); // 探测时间间隔 setsockopt(sockfd, SOL_TCP, TCP_KEEPINTVL, (char *)&keepInterval, sizeof(keepInterval)); // 探测次数 setsockopt(sockfd, SOL_TCP, TCP_KEEPCNT, (char *)&keepCount, sizeof(keepCount) -
-
应用程序探活
开启系统Keep-Alive机制有时并不能很好的检测对端应用程序还能消息响应,TCP keepalive处于传输层,由操作系统负责,能够判断进程存在,网络通畅,但无法判断对端进程阻塞或死锁等问题,所以就需要由 应用程序探活
通常在应用程序定义2个Keep-Alive消息结构,一个是Keep-Alive request,一个是Keep-Alive response,定时向对端发送这个消息,如果对端回复了Keep-Alive response消息则重置定时器
小数据包
在实际应用程序中可能有很多小数据包,例如消息数据里只包含一个2字节的id,对于发送大量的小数据包对带宽使用率有一定影响
小数据包,指的是长度小于最大报文段长度 MSS 的 TCP 分组
在应对小数据包时,有个优化算法——Nagle 算法,Nagle算法的本质其实就是限制大批量的小数据包同时发送,为此,它提出在任何一个时刻,未被确认的小数据包不能超过一个。 这样,发送端就可以把接下来连续的几个小数据包存储起来,等待接收到前一个小数据包的 ACK 分组之后,再将数据一次性发送出去
但是对于即时游戏,或者不能接受高延时的产品来讲,使用Nagle算法,无疑增加了消息延时,这时可以考虑是否禁用Nagle算法:
int network::SocketWrapper::SetNoDelay(bool nodelay)
{
int arg = int(nodelay);
return setsockopt(socket_, IPPROTO_TCP, TCP_NODELAY, (char*)&arg, sizeof(int));
}
对于延时不那么敏感的产品,打开Nagle算法反而提高了带宽的利用率
同时有个机制是提高带宽的利用率——延时ACK,延时 ACK 在收到数据后并不马上回复,而是累计需要发送的 ACK 报文,等到有数据需要发送给对端时, 将累计的 ACK捎带一并发送出去。当然,延时 ACK 机制,不能无限地延时下去,否则发送端误认为数据包没有发送成功,引起重传,反而会占用额外的网络带宽
通过对Nagle算法和延时ACK的了解,Nagle算法和延时ACK两个优化组合在一起,反而引起了高延时,以Nagle算法和延时ACK两个组合在一起来分析,如下:
- 客户端应用程序先发送1个小数据包,接着又发送1个小数据包
- 服务端收到小数据包,先不回复ACK,直到达到延时时间
- 在服务端延时的这段时间,由于客户端没有收到第一个小数据包的ACK,那么客户端的第2个小数据包处于等待发送
- 在服务端达到延时时间,客户端收到ACK,客户端才发送第2个小数据包
TCP 报文解析
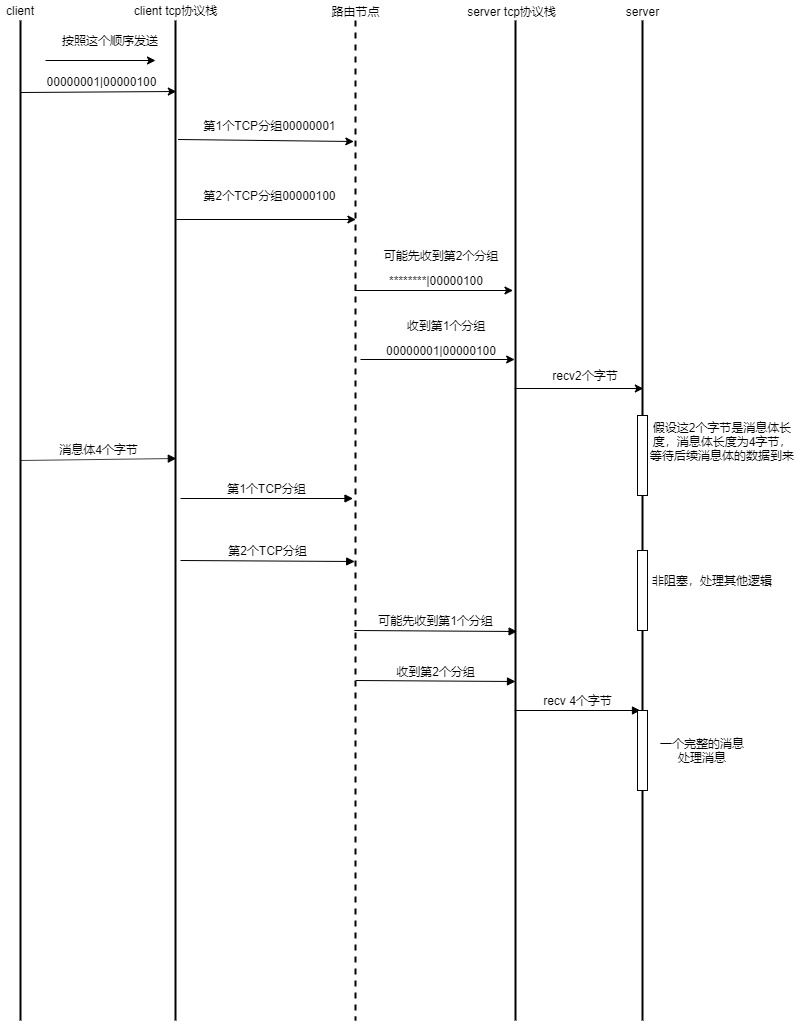
TCP 是一种流式协议,更好的理解流式协议,可以形象的理解成一条河流(二进制),河水流经应用程序时,把河水存储到水池(消息buff池),这个水池是有顺序的组织水,先流进来的水放在第一位,依次排列, 应用程序处理这些有序的水流时,怎么知道截取多长的水流才是属于一个完整的消息呢?从源头(发送端)流出来的水流是不是有顺序的呢?
-
从源头(发送端)流出来的水流是不是有顺序的呢
应用程序发送时保证顺序发送,但是经过各种网络设备后,水流到接收端有可能是无序的
幸运的是,TCP协议为我们保证了也是按照发送端的顺序反应给接收端应用程序,在按照顺序反应给接收端应用程序之前, 如果发送过程中有 TCP 分组丢失,但是其后续分组陆续到达,那么 TCP 协议栈会缓存后续分组,直到前面丢失的分组到达
-
怎么知道截取多长的水流才是属于一个完整的消息呢?
服务端应用程序和客户端应用程序之间通常定义一种消息格式,通常由消息id、消息长度,消息体组成,发送端应用程序发送时保证按照先发送消息id、消息长度、消息体的顺序发送, 那么发应给接收端应用程序的顺序也是这样的消息id、消息长度、消息体。一次recv有可能只接收到消息id,或者只接收了消息id的一半的字节长度,例如消息id为2个字节,一次recv有可能只接收了1字节, 那么接收端应用程序继续等待下面的字节到来,等待这期间可以继续做其他工作(非阻塞),当接收了消息id、消息长度,拿到消息长度继续等待消息体,消息体到达后,消息id、消息长度,消息体组合在一起 就是一个完整消息了
下面定义了一个消息:
struct BuffMsgBase { BuffMsgBase(MessageID id, MessageLength l) : msg_id(id), msg_len(l) { } MessageLength MsgLen()const { return msg_len; } MessageID MsgId()const { return msg_id; } MessageID msg_id; MessageLength msg_len; }; struct MsgS2C0407 : public network::BuffMsgBase { MsgS2C0407() :network::BuffMsgBase(3, sizeof(MsgS2C0407)), id(0) {} int id; };
结合上面的分析,下面给出了一个完整消息从发送端到接收端的时序图:
字节序问题
高字节存放在起始地址,叫做大端字节序Big-Endian
低字节存放在起始地址,叫做小端字节序Little-Endian
例如两字节的整型0x0201,对应的二进制0000001000000001:
大端字节序:0x02 高字节存放在起始地址
小端字节序:0x01 低字节存放在起始地址
如图:

数据在网络中传输采用的是大端字节序,对于单字节的数据在网络中传输,两端不需要关心字节序的问题, 如果大于1字节的数据,并且网络的两端主机字节序相同的情况下(两端要么都是小端字节序,要么都是大端字节序), 通过网络传输没有问题,如果网络的两端主机字节序不同,就会数据错误, 通常两端约定一种顺序,要么约定大端字节序,要么约定小端字节序
以下列字节序为例说明:
-
两端都采用小端字节序,当需要通过网络传输一个short型数据,值为1001
发送端对应二进制:11101001 00000011,由于是小端字节序,第一个字节11101001 第二个字节00000011
写到buf池时,先写入11101001,再写入00000011
接收端先接收到11101001,再接收到00000011,接收端拷贝sizeof(short)大小的数据给本地变量,本地变量对应的二进制也同样是 11101001 00000011,所以本地变量的值也是1001
-
两端采用的字节序不同,发送端是大端字节序,接收端是小端字节序,同样需要传输一个short型数据,值为1001
发送端对应二进制:00000011 11101001,由于是大端字节序,第一个字节00000011 第二个字节11101001
写到buf池时,先写入00000011,再写入11101001
接收端先接收到00000011,再接收到11101001,接收端拷贝sizeof(short)大小的数据给本地变量,本地变量对应的二进制是 00000011 11101001,由于接收端是小端字节序,如果本地变量是个有符号变量,值为-26883
为了避免错误,通常都约定为大端字节序,即发送时从本机字节序转换为大端字节序,接收时从大端字节序转换为本机字节序
POSIX 标准提供了如下的转换函数:
uint16_t htons (uint16_t hostshort)
uint16_t ntohs (uint16_t netshort)
uint32_t htonl (uint32_t hostlong)
uint32_t ntohl (uint32_t netlong)
转换函数中的 n 代表的就是 network,h 代表的是 host,s 表示的是 short,l 表示的是 long,分别表示 16 位和 32 位的整数
如果主机和网络字节序一样,这些函数转换只是空实现:
# if __BYTE_ORDER == __BIG_ENDIAN
/* The host byte order is the same as network byte order, so these functions are all just identity. */
# define ntohl(x) (x)
# define ntohs(x) (x)
# define htonl(x) (x)
# define htons(x) (x)
例如在初始化socket地址结构中,因为端口是2字节数据,所以指定端口使用的是htons(port)
这里是开源的字节序库,功能更完善