InnoDB系统表空间
除了独立表空间还有系统表空间,独立表空间可以参考这篇文章,系统表空间结构如图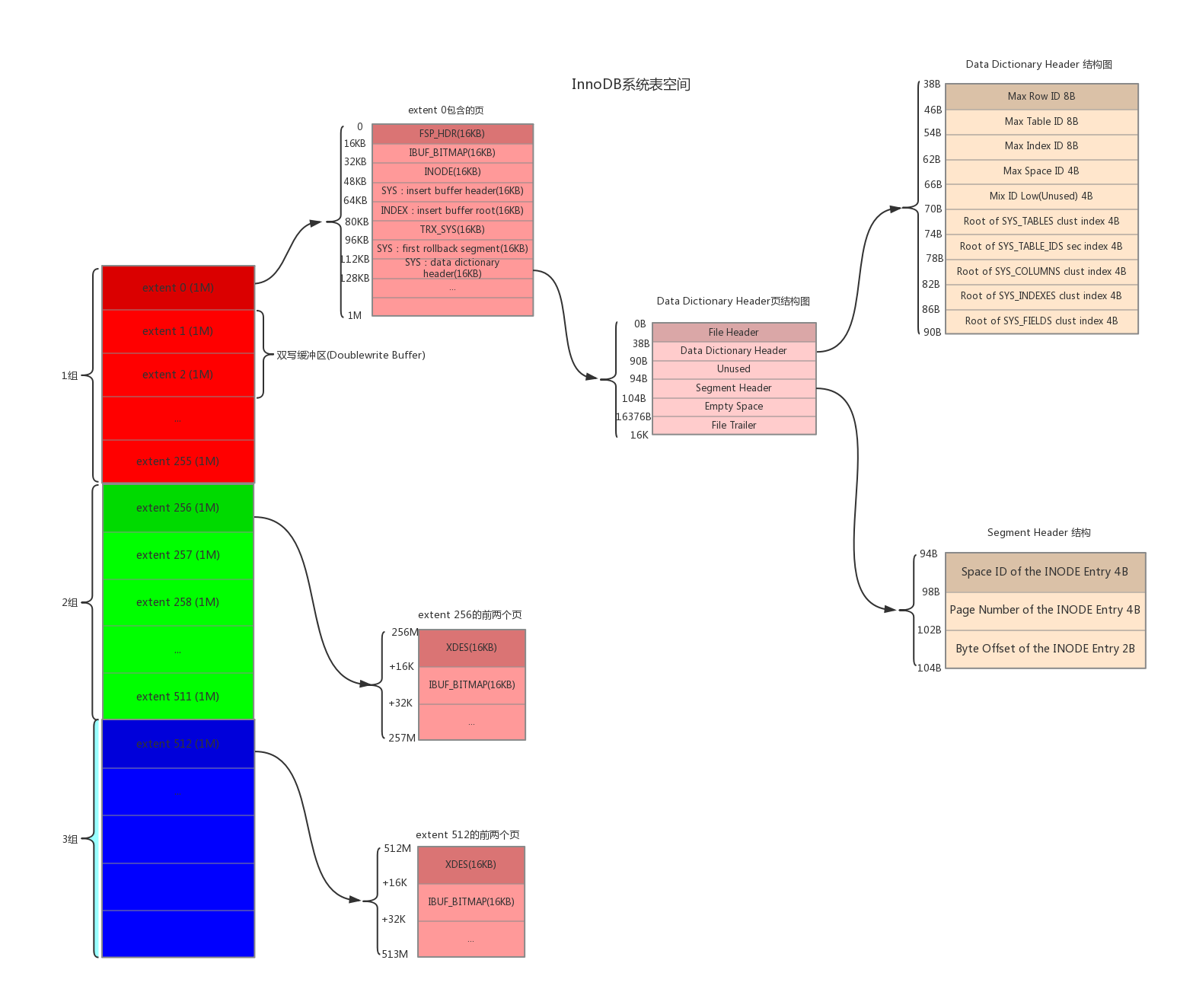
与独立表空间的差别
与独立表空间的结构图对比下来,系统表空间的第一组的第一区的前三个页面类型一样,只是页号为3~7的页面是系统表空间特有的
| 页号 | 名称 | 页面类型 | 描述 |
|---|---|---|---|
| 3 | Insert Buffer Header | SYS | 存储Insert Buffer的头部信息 |
| 4 | Insert Buffer Root | INDEX | 存储Insert Buffer的根页面 |
| 5 | Transction System | TRX_SYS | 事务系统的相关信息 |
| 6 | First Rollback Segment | SYS | 第一个回滚段的页面 |
| 7 | Data Dictionary Header | SYS | 数据字典头部信息 |
除了这几个记录系统属性的页面之外,系统表空间的extent 1和extent 2这两个区,也就是页号从64~191这128个页面被称为双写缓冲区(Doublewrite buffer)
数据字典
MySQL有些系统表保存着整个InnoDB的用户数据表、系统表属性、表内列的属性、表索引的属性等等,这些数据称为元数据
| 表名 | 描述 |
|---|---|
| SYS_TABLES | 整个InnoDB存储引擎中所有的表的信息 |
| SYS_COLUMNS | 整个InnoDB存储引擎中所有的列的信息 |
| SYS_INDEXES | 整个InnoDB存储引擎中所有的索引的信息 |
| SYS_FIELDS | 整个InnoDB存储引擎中所有的索引对应的列的信息 |
| SYS_FOREIGN | 整个InnoDB存储引擎中所有的外键的信息 |
| SYS_FOREIGN_COLS | 整个InnoDB存储引擎中所有的外键对应列的信息 |
| SYS_TABLESPACES | 整个InnoDB存储引擎中所有的表空间信息 |
| SYS_DATAFILES | 整个InnoDB存储引擎中所有的表空间对应文件系统的文件路径信息 |
| SYS_VIRTUAL | 整个InnoDB存储引擎中所有的虚拟生成列的信息 |
这些系统表也被称为数据字典,它们都是以B+树的形式保存在系统表空间的某些页面中,其中SYS_TABLES、SYS_COLUMNS、SYS_INDEXES、SYS_FIELDS这四个表尤其重要,称之为基本系统表(basic system tables)
SYS_TABLES表:
SYS_TABLES表有两个索引:
-
以NAME列为主键的聚簇索引
-
以ID列建立的二级索引
| 列名 | 描述 |
|---|---|
| NAME | 表的名称 |
| ID | InnoDB存储引擎中每个表都有一个唯一的ID |
| N_COLS | 该表拥有列的个数 |
| TYPE | 表的类型,文件格式、行格式、压缩等信息 |
| MIX_ID | 已过时 |
| MIX_LEN | 表的一些额外的属性 |
| CLUSTER_ID | 未使用 |
| SPACE | 该表所属表空间的ID |
SYS_COLUMNS表
SYS_COLUMNS表有一个聚簇索引————以(TABLE_ID, POS)列为主键的聚簇索引
| 列名 | 描述 |
|---|---|
| TABLE_ID | 该列所属表对应的ID |
| POS | 该列在表中是第几列 |
| NAME | 该列的名称 |
| MTYPE | main data type,主数据类型,就是那堆INT、CHAR、VARCHAR、FLOAT、DOUBLE等 |
| PRTYPE | precise type,精确数据类型,就是修饰主数据类型的那堆东东,例如是否允许NULL值,是否允许负数 |
| LEN | 该列最多占用存储空间的字节数 |
| CLUSTER_ID | 未使用 |
| PREC | 该列的精度 |
SYS_INDEXES表
SYS_INDEXES表有一个聚簇索引————以(TABLE_ID, ID)列为主键的聚簇索引
| 列名 | 描述 |
|---|---|
| TABLE_ID | 该列所属表对应的ID |
| ID | InnoDB存储引擎中每个索引都有一个唯一的ID |
| NAME | 该索引的名称 |
| N_FIELDS | 该索引包含列的个数 |
| TYPE | 该索引的类型,例如聚簇索引、唯一索引、更改缓冲区的索引、全文索引、普通的二级索引等等各种类型 |
| SPACE | 该索引根页面所在的表空间ID |
| PAGE_NO | 该索引根页面所在的页面号 |
| MERGE_THRESHOLD | 如果页面中的记录被删除到这个比例,就把该页面和相邻页面合并 |
SYS_FIELDS表
SYS_FIELDS表有一个聚簇索引————以(INDEX_ID, POS)列为主键的聚簇索引
| 列名 | 描述 |
|---|---|
| INDEX_ID | 该索引列所属的索引的ID |
| POS | 该索引列在某个索引中是第几列 |
| COL_NAME | 该索引列的名称 |
这些系统表是通过系统数据库information_schema中以innodb_sys开头的表呈现给MySQL client的,在information_schema数据库中的这些以INNODB_SYS开头的表并不是真正的内部系统表(内部系统表是上边提到的以SYS开头的那些表), 而是在存储引擎启动时读取这些以SYS开头的系统表,然后填充到这些以INNODB_SYS开头的表中。以INNODB_SYS开头的表和以SYS开头的表中的字段并不完全一样, 例如INNODB_SYS_TABLES表中列FILE_FORMAT、ROW_FORMAT、ZIP_PAGE_SIZE是对SYS_TABLES表中列TYPE数据解析后的结果
上面提到这些系统表存储着用户数据表、系统数据表的元数据,而这4个表的元数据是硬编码到代码中,同时InnoDB在固定的页面来记录这4个表的聚簇索引和二级索引对应的B+树位置, 这个页面就是页号为7的页面,类型为SYS,记录了Data Dictionary Header,也就是数据字典的头部信息。除了这4个表的5个索引的根页面信息外,这个页号为7的页面还记录了整个InnoDB存储引擎的一些全局属性, Data Dictionary Header页结构图就是页号为7的页面结构
页结构中Segment Header记录本页面所在段对应的INODE Entry位置信息
页结构中Data Dictionary Header记录一些基本系统表的根页面位置以及InnoDB存储引擎的一些全局信息:
-
Max Row ID
Max Row ID是全局共享的,如果不显式的为表定义主键,而且表中也没有UNIQUE索引,那么InnoDB存储引擎会默认生成一个名为row_id的列作为主键。 因为它是主键,所以每条记录的row_id列的值不能重复。原则上只要一个表中的row_id列不重复就可以 ,当向表插入一条记录时,该记录的row_id列的值就是Max Row ID对应的值,然后再把Max Row ID对应的值加1
-
Max Table ID
InnoDB存储引擎中的所有的表都对应一个唯一的ID,每次新建一个表时,就会把本字段的值作为该表的ID,然后自增本字段的值
-
Max Index ID
InnoDB存储引擎中的所有的索引都对应一个唯一的ID,每次新建一个索引时,就会把本字段的值作为该索引的ID,然后自增本字段的值
-
Max Space ID
InnoDB存储引擎中的所有的表空间都对应一个唯一的ID,每次新建一个表空间时,就会把本字段的值作为该表空间的ID,然后自增本字段的值
-
Root of SYS_TABLES clust index
本字段代表SYS_TABLES表聚簇索引的根页面的页号
-
Root of SYS_TABLE_IDS sec index
本字段代表SYS_TABLES表为ID列建立的二级索引的根页面的页号
-
Root of SYS_COLUMNS clust index
本字段代表SYS_COLUMNS表聚簇索引的根页面的页号
-
Root of SYS_INDEXES clust index
本字段代表SYS_INDEXES表聚簇索引的根页面的页号
-
Root of SYS_FIELDS clust index
本字段代表SYS_FIELDS表聚簇索引的根页面的页号